Monitorización¶
La monitorización en Zentyal¶
El módulo de monitorización permite al administrador conocer el estado del uso de los recursos del servidor Zentyal. Esta información es esencial tanto para diagnosticar problemas como para planificar los recursos necesarios con el objetivo de evitar problemas.
La monitorización se realiza mediante gráficas que permiten hacerse fácilmente una idea de la evolución del uso de recursos. Podremos acceder a las gráficas desde Monitorización. Colocando el cursor encima de algún punto de la línea de la gráfica en la que estemos interesados podremos saber el valor exacto para un momento determinado.
Podemos elegir la escala temporal de las gráficas entre una hora, un día, un mes o un año. Para ello simplemente pulsaremos sobre la pestaña correspondiente.
Pestañas con los diferentes informes de monitorización
Métricas¶
Carga del sistema¶
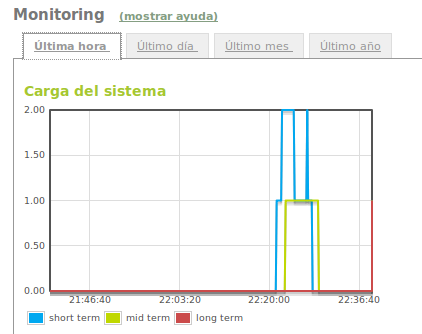
La carga del sistema trata de medir la relación entre la demanda de trabajo y el realizado por el computador. Esta métrica se calcula usando el número de tareas ejecutables en la cola de ejecución y es ofrecida por muchos sistemas operativos en forma de media de uno, cinco y quince minutos.

Gráfica de la carga del sistema
Uso de la CPU¶
Con esta gráfica tendremos una información detallada del uso de la CPU. En caso de que dispongamos de una maquina con múltiples CPUs tendremos una gráfica para cada una de ellas.
En la gráfica se representa la cantidad de tiempo que pasa la CPU en alguno de sus estados, ejecutando código de usuario, código del sistema, estamos inactivo, en espera de una operación de entrada/salida, entre otros valores. Ese tiempo no es un porcentaje sino unidades de scheduling conocidos como jiffies. En la mayoría de sistemas Linux ese valor es 100 por segundo pero nada garantiza que no pueda ser diferente.
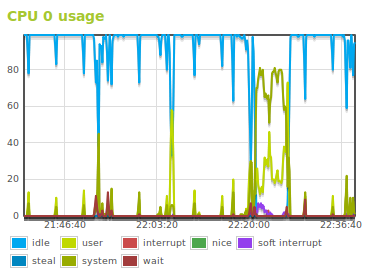
Gráfica de uso de la CPU
Uso de la memoria¶
La gráfica nos muestra el uso de la memoria. Se monitorizan cuatro variables:
- Memoria libre:
- Cantidad de memoria no usada
- Caché de pagina:
- Cantidad destinada a la caché del sistema de ficheros
- Buffer caché:
- Cantidad destinada a la caché de los procesos
- Memoria usada:
- Memoria usada que no está destinada a ninguno de las dos anteriores cachés.

Gráfica del uso de memoria
Uso del sistema de ficheros¶
Esta gráfica nos muestra el espacio usado y libre del sistema de ficheros en cada punto de montaje.
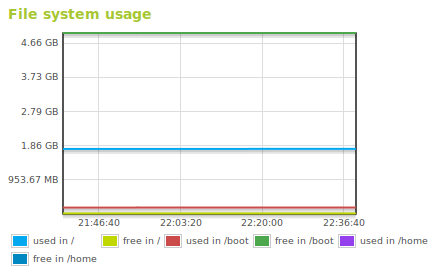
Gráfica del uso del sistema de ficheros
Temperatura¶
Con esta gráfica es posible leer la información disponible sobre la temperatura del sistema en grados centígrados usando el sistema ACPI [1]. Para que esta métrica se active, es necesario que la máquina disponga de este sistema y que el kernel lo soporte.
| [1] | La especificación Advanced Configuration and Power Interface (ACPI) es un estándar abierto para la configuración de dispositivos centrada en sistemas operativos y en la gestión de energía del computador. http://www.acpi.info/ |
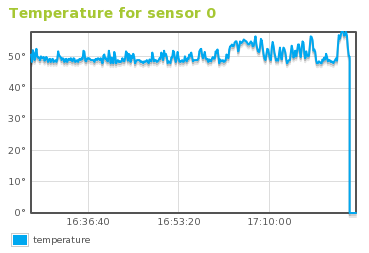
Gráfica del diagrama del sensor del temperatura
Alertas¶
La monitorización carecería en gran medida de utilidad si no estuviera acompañada de un sistema de notificaciones que nos avisara cuando se producen valores anómalos, permitiéndonos saber al momento que la máquina está sufriendo una carga inusual o está llegando a su máxima capacidad.
Las alertas de monitorización deben configurarse en el módulo de eventos. Entrando en Eventos ‣ Configurar eventos, podemos ver la lista completa, los eventos de monitorización están agrupados en el evento Monitor.
Pantalla de configuración de los observadores de la monitorización
Pulsando en la celda de configuración, accederemos a la configuración de este evento. Podremos elegir cualquiera de las métricas monitorizadas y establecer umbrales que disparen el evento.

Pantalla de configuración de los umbrales de eventos
En cuanto a los umbrales tendremos de dos tipos, de advertencia y de fallo, pudiendo así discriminar entre la gravedad del evento. Tenemos la opción de invertir, lo que hará que los valores que estén dentro del umbral sean considerados fallos y lo contrario si están fuera. Otra opción importante es la de persistente:. Dependiendo de la métrica también podremos elegir otros parámetros relacionados con esta, por ejemplo para el disco duro podemos recibir alertas sobre el espacio libre, o para la carga puede ser útil la carga a corto plazo, etc.
Cada medida tiene una métrica que se describe como sigue:
- Carga del sistema:
- Los valores se deben establecer en número de tareas en la cola de ejecución.
- Uso de la CPU:
- Los valores se deben establecer en jiffies o unidades de scheduling.
- Uso de la memoria física:
- Los valores deben establecerse en bytes.
- Sistema de ficheros:
- Los valores deben establecerse en bytes.
- Temperatura:
- Los valores a establecer debe establecer en grados.
Una vez configurado y activado el evento deberemos configurar al menos un observador para recibir las alertas. La configuración de los observadores es igual que la de cualquier evento, así que deberemos seguir las indicaciones contenida en el capítulo de Eventos y alertas.